How Model Routing Cuts AI Costs by 30–70%
A frontier model answering a question a cheaper one could handle is the biggest quiet line on most AI bills. Model routing, explained: the four steps, the tier-price math, and the 30-70% it recovers.

A mechanism guide for engineering and platform teams: how routing works, why it saves money, and where it goes wrong.
Most AI bills are inflated by the same quiet waste: a frontier model answering a question a model one-twentieth the price could have answered just as well. Sentiment tags, intent classification, short rewrites, routine extraction, boilerplate summaries, all of it billed at GPT-5 or Claude Opus rates because the application hard-codes one model for every call. Alephant tracks this failure mode as model overkill, and on mixed workloads it is usually the single largest line of recoverable spend.
Model routing is the lever that removes it. This post is the mechanism: what routing is, the four steps it runs on every request, the price math that makes it work, the strategies you can route by, and the failure modes nobody puts in the marketing copy.
TL;DR
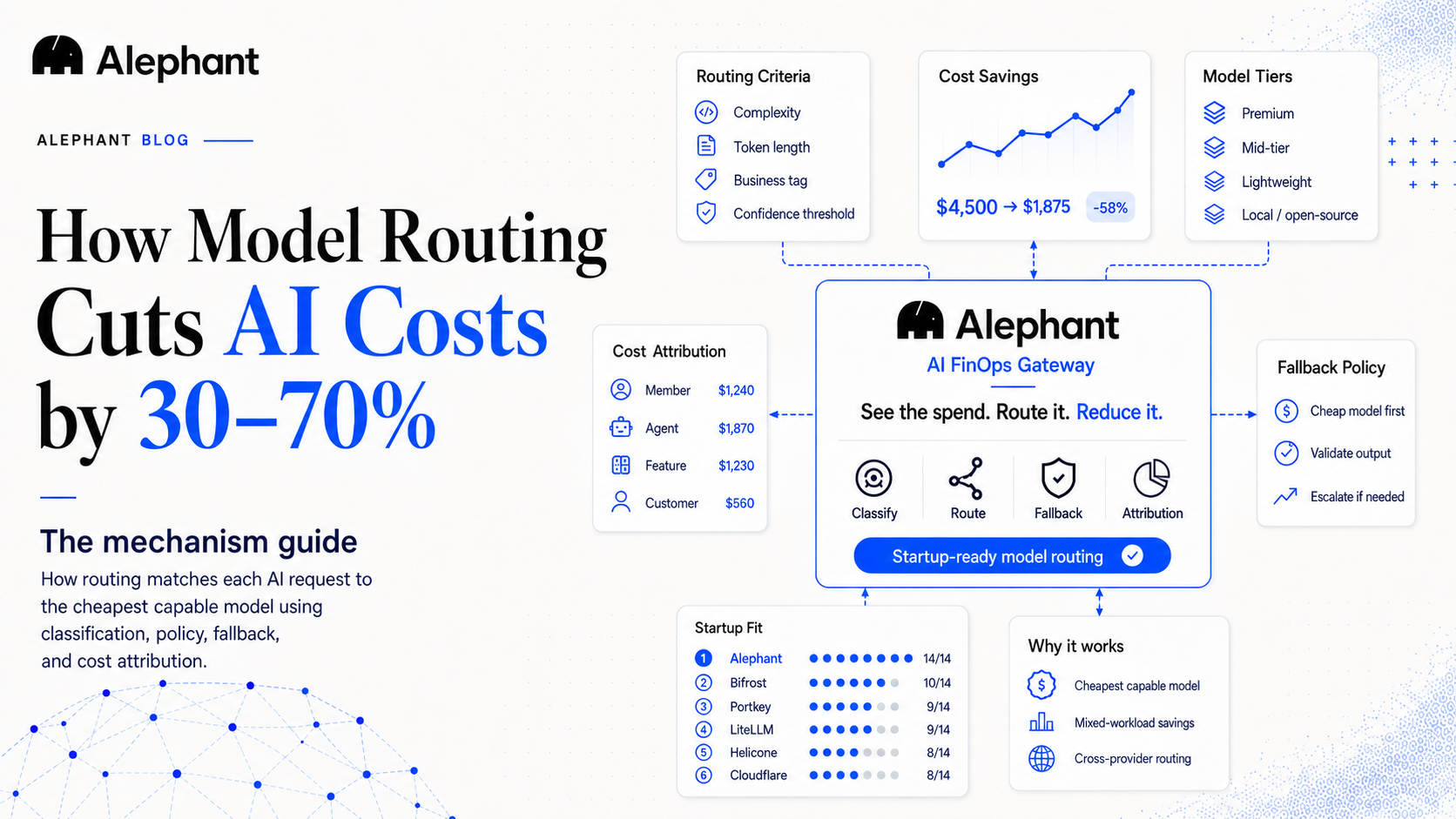
Model routing is the cost lever that matches each AI request to the cheapest model that can answer it correctly, instead of sending everything to a frontier model. Intelligent model routing delivers 30–70% cost reduction on mixed workloads, with aggressive routing to free-tier or local models reaching 98% on specific workloads (per MindStudio and the Avengers-Pro routing research, arxiv 2508.12631). It works because model prices span three orders of magnitude: premium models run $30–60 per million tokens while lightweight models run $0.50–2 and local deployment costs near $0.0001. Routing captures that spread automatically, at the gateway, with no application code changes.
What is model routing?
Model routing is the practice of automatically sending each AI request to the cheapest model that can answer it correctly. A router classifies the incoming request by complexity, token length, or business tag, then dispatches simple work to lightweight models and reserves frontier models for the requests that genuinely need them. The decision happens on the wire, per request, before the provider bill is incurred.
The contrast is with the default architecture, where one model is wired into the application and every call pays that model's price regardless of difficulty. Routing replaces "one model for everything" with "the right tier for each request."
Why routing saves money: the tier cost ladder
Routing works because of a fact most teams never price out: the gap between the most expensive and the cheapest capable model is enormous.
Premium models (GPT-5, Claude Opus) cost $30–60 per million tokens. Mid-tier (GPT-5 mini, Claude Sonnet) cost $10–15. Lightweight (Haiku, GPT-3.5-class) cost $0.50–2. Small open-source (Llama, Mistral) cost $0.10–0.50. Local deployment costs roughly $0.0001. (Source: MindStudio, Datacamp, web validation May 2026.)
| Tier | Example models | Cost / million tokens | What it is for |
|---|---|---|---|
| Premium | OpenAI GPT-5, Anthropic Claude Opus | $30–60 | Hard multi-step reasoning, long-context synthesis |
| Mid-tier | GPT-5 mini, Claude Sonnet | $10–15 | Most production reasoning |
| Lightweight | Claude Haiku, GPT-3.5-class | $0.50–2 | Classification, extraction, short rewrites |
| Small open-source | Meta Llama, Mistral | $0.10–0.50 | High-volume routine calls |
| Local | Self-hosted open weights | ~$0.0001 | Bulk, latency-tolerant, privacy-sensitive |
That is a five-rung ladder with order-of-magnitude jumps between the top and the bottom. A request that costs $45 per million tokens on a premium model costs around $1.25 per million on a lightweight one. When a meaningful share of your traffic is routine, sending it down the ladder is the difference between a $4,500 month and a $1,900 one. The next section shows that arithmetic.
How model routing works: the four steps
A router runs the same four steps on every request. None of them require the application to know which model it will hit.
1. Classify. The router inspects the request and assigns it a class. Classification can be cheap and heuristic (token length, a keyword or tag on the request) or learned (a small classifier model or an embedding-based score that predicts difficulty). The goal is one decision: how hard is this, really?
2. Match to policy. The class maps to a model tier through a routing policy you define. "Classification and extraction go to a lightweight model. Customer-facing reasoning goes to mid-tier. Anything tagged escalated goes to a frontier model." The policy is configuration, not code.
3. Route on the wire. The gateway dispatches the request to the chosen model and returns the response in the provider's native shape. Because the gateway speaks to 60+ providers through one API, routing can cross providers, not just models inside one vendor. BYO-KEY keeps each provider call on the customer's own keys.
4. Fall back or escalate. Good routers do not trust the cheap model blindly. A cascade policy sends the request to a lightweight model first, checks the answer against a confidence signal or a cheap validator, and escalates to a stronger model only when the first answer fails the check. You pay frontier prices only for the fraction of requests that actually need them.
Step 4 is what separates real routing from a static rule. It is also where the research numbers come from: a well-tuned cascade keeps accuracy high while paying lightweight prices on the majority of calls.
A worked example (arithmetic on published list prices)
This is an illustration computed from the list prices in the ladder above, not measured Alephant telemetry. It shows where the 30–70% range comes from.
Take a workload of 100 million tokens per month. Without routing, every token hits a premium model at a blended $45 per million. With routing, 60% of the traffic is routine enough for a lightweight model at a blended $1.25 per million, and 40% stays on the premium model.
| Scenario | Premium tokens | Lightweight tokens | Monthly cost |
|---|---|---|---|
| No routing (all premium) | 100M × $45/M | 0 | $4,500 |
| Routed (60% lightweight) | 40M × $45/M | 60M × $1.25/M | $1,875 |
That is a 58% reduction on the same workload, with no application code changed. Push the routable share higher (toward the 98% edge case the research reports for free-tier and local routing) and the savings climb further; keep it conservative and you land lower in the band. The lever scales with how much of your traffic is genuinely routine, which on most production workloads is more than teams expect.
A second-order effect makes routing matter even more: output tokens cost 4–6x more than input tokens (source: OpenAI realtime cost guide). Routine calls tend to be output-heavy relative to their value, so moving them to a cheaper tier compounds with the output-token asymmetry rather than just the headline per-token price.
What you can route by
Routing policies are built from a small set of signals, used alone or in combination.
- Complexity. The most common axis. Simple Q&A, classification, and extraction go to lightweight models; multi-step reasoning and long-context synthesis go to frontier models.
- Token length / context size. A 200-token request and a 180,000-token request rarely belong on the same model. Length is a cheap, reliable first-cut signal.
- Business tag. Route by who or what is calling: customer tier, feature, environment (staging on cheap models, production on the good ones), or per-agent policy. This is routing as a policy decision, not just a model-quality one.
- Semantic class. An embedding of the request predicts its category, and the category maps to a tier. This catches difficulty that raw length misses.
- Cascade / confidence. Cheap model first, escalate on low confidence. The fallback strategy from step 4, expressed as a policy.
A model whitelist sits over all of these: it constrains which models the router is even allowed to select, so a routing policy can never quietly send regulated traffic to an unapproved provider.
Where model routing goes wrong (and how to prevent it)
The honest version of the quality question: does sending requests to cheaper models make the answers worse? Only if you route badly.
The risk is real. Send a hard reasoning task to a lightweight model and you get a confident wrong answer, which is worse than an expensive right one. Three things keep that from happening:
- Cascade over static rules. A confidence check with escalation means the cheap model only "wins" when its answer holds up. The research bears this out: Avengers-Pro routing can match GPT-5-medium accuracy at 27% lower cost (arxiv 2508.12631), because the hard requests still reach a strong model.
- Evaluation, continuously. A tier that was adequate at launch can drift after a prompt change or a model update. Routing without an eval loop is how quality erodes silently. Treat the routing policy as something you measure, not something you set once.
- A whitelist and a floor. Some request classes should never be routed down, no matter what the classifier says. Encode that as a hard floor rather than trusting the policy to get it right every time.
Routing also has costs of its own to account for: the classifier adds a small amount of latency and, if it is a model rather than a heuristic, a small amount of token spend. On any workload where the price gap between tiers is an order of magnitude, that overhead is rounding error. On a workload that is already all-lightweight, routing has nothing to capture and you should not bother.
How routing fits the rest of the cost stack
Routing is one of six cost levers, and it pairs most naturally with caching. The two solve different halves of the problem:
- Caching handles requests you have seen before. Exact-match caching catches identical repeats, semantic dedup catches paraphrases, and native prompt caching discounts shared prefixes on novel calls.
- Routing handles the novel requests caching cannot serve, by sending each to the cheapest model that can answer it.
A request that misses every cache layer still gets routed; a request that hits a cache never pays for a model at all. Stacked, they cover far more of the spend surface than either alone. The full four-pillar context for where these levers sit is in the AI FinOps definitive guide; prompt compression and prompt template caching round out the six.
How to set up model routing on Alephant
Model routing is a live beta feature, configured from the console with no application code changes. The mechanics:
- Point traffic at the router path. Requests flow through the Alephant gateway router endpoint (
/router/{id}/*), so the routing decision happens at the gateway, not in your app. - Define the policy. Set the routing rules by complexity, token length, or business tag, and bound them with a model whitelist so routing can only select approved models. Routing can cross providers.
- Measure the gain. Route Optimization is the AI Inside signal that quantifies realized savings from routing, and the model-overkill signal flags the requests still going to an oversized model. Both live in AI Inside, which is a Pro+ feature.
Alephant claims 40–70% cost savings on mixed workloads for its routing; the broader independent research range is 30–70%, with the higher numbers reserved for aggressive free-tier and local routing. Either way, the prerequisite is the same: a gateway in the request path with cost attribution turned on, so you can see which requests are overpaying before you route them.
FAQ
How does model routing work?
Model routing runs four steps on every request: classify the request by complexity, token length, or business tag; match the class to a model tier through a routing policy; route the request on the wire through a gateway that can reach many providers; and fall back to a stronger model only if the cheap model's answer fails a confidence check. The result is that simple requests pay lightweight-model prices while only genuinely hard requests reach a frontier model.
How much can model routing save?
Independent research puts intelligent model routing at 30–70% cost reduction on mixed workloads, with aggressive routing to free-tier or local models reaching 98% on specific workloads (MindStudio, Avengers-Pro research, arxiv 2508.12631). The savings scale with how much of your traffic is routine: the more requests that can safely move to a cheaper tier, the higher the reduction. A worked illustration on published list prices, with 60% of traffic routed to a lightweight model, yields about 58%.
What is the difference between model routing and prompt caching?
Prompt caching reduces the cost of requests you have seen before by reusing cached prefixes or cached responses. Model routing reduces the cost of novel requests by sending each to the cheapest model that can answer it. Caching answers "have I done this already?"; routing answers "what is the cheapest model that can do this?" They are complementary and most teams run both.
Does model routing hurt answer quality?
Only if the routing is static and untested. A cascade policy sends requests to a cheap model first and escalates to a stronger model when a confidence check fails, which keeps hard requests on capable models. Research shows a tuned router can match a strong model's accuracy at materially lower cost (Avengers-Pro at 27% lower cost than GPT-5-medium). Quality erosion comes from routing without an evaluation loop, not from routing itself.
How do I set up model routing?
Put a gateway in the request path, point traffic at its router endpoint, and define a routing policy by complexity, token length, or business tag, bounded by a model whitelist. On Alephant this is zero-code configuration through the console router path, and routing can cross providers. Turn on cost attribution first so you can see which requests are overpaying before you route them.
Can model routing switch between different providers?
Yes. A gateway that speaks to many providers through one API can route across vendors, not just between models inside a single provider, so a request can go to a lightweight open-source model on one provider and a frontier model on another under the same policy. With BYO-KEY, each provider call runs on the customer's own keys.
Sources
- MindStudio, Morph LLM Router, and Avengers-Pro routing research, arxiv 2508.12631: the 30-70% range, the 98% edge case, and the GPT-5-medium accuracy-match-at-27%-lower-cost figure.
- MindStudio and Datacamp tier-pricing summaries (web validation, May 2026): the five-rung tier cost ladder.
- OpenAI realtime cost guide: output tokens cost 4-6x input tokens.
- Alephant live capability surface as of 2026-06-06, including the 40-70% routing claim and the live beta state of model routing.
Related reading
- What Is AI FinOps? The 2026 Definitive Guide: the four pillars of AI FinOps and where the six cost levers sit.
- Meet Alephant: The AI FinOps Gateway: what Alephant is and how the gateway works.